
✔NVIDIA представила ИИ, который генерирует видео с высоким разрешением по текстовому описанию - «Новости сети»
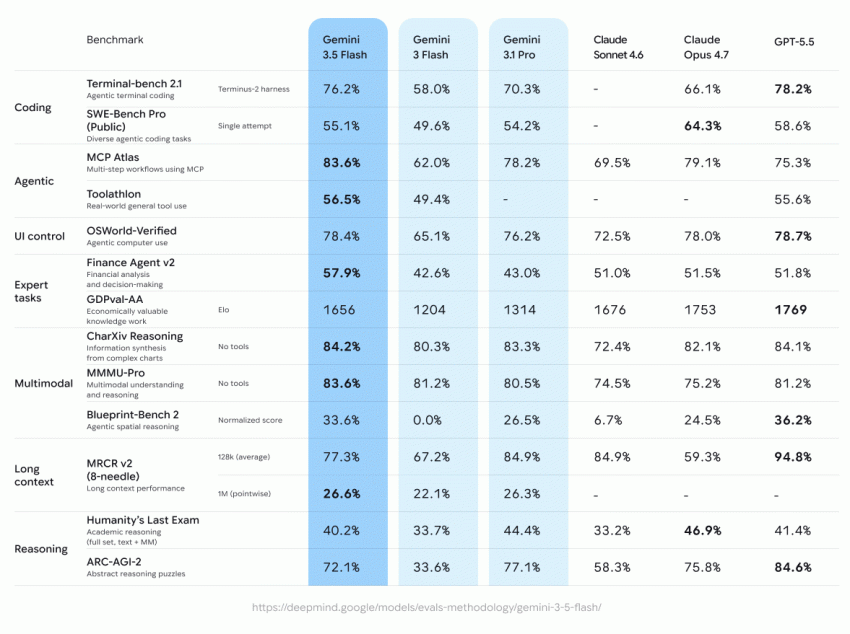
NVIDIA представила свою ИИ-модель для превращения текста в видео под названием VideoLDM, разработанную в сотрудничестве с исследователями из Корнельского университета. Модель способна генерировать видео в разрешении до 2048 × 1280 пикселей с частотой 24 кадра и длительностью до 4,7 секунд на основе текстового описания.

Источник изображений: NVIDIA
В основе модели лежат наработки нейросети Stable Diffusion. Решение NVIDIA имеет до 4,1 млрд параметров, но только 2,7 млрд из этих них использовали видео для тренировки. Это весьма скромно по меркам современных ИИ. Тем не менее, с помощью эффективного подхода к модели скрытой диффузии (LDM — Latent diffusion model) разработчики смогли создавать разнообразные и согласованные во времени видео высокого разрешения с весьма высоким качеством.
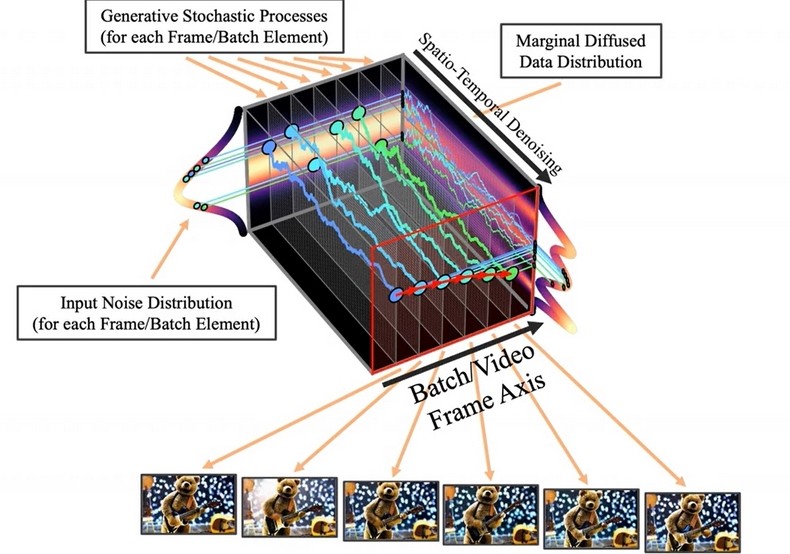
Исследователи выделяют следующие особенности данной модели: генерацию персонализированного видео и свёрточный синтез во времени. Временные слои, которые были обучены в VideoLDM для превращения текста в видео, вставляются в опорные сети LDM изображений, которые заранее точно настроены в наборе изображений DreamBooth. Временные слои обобщаются контрольными точками DreamBooth, что позволяет персонализировать преобразование текста в видео. Применяя изученные временные слои сверточно во времени, можно получить клипы чуть большей продолжительности с незначительным ухудшением качества.
Модель также способна генерировать видео сцен вождения. Видеоролики имеют разрешение 1024 × 512 точек и длительностью до 5 минут. Есть возможность моделирования конкретного сценария вождения, когда за основу берутся ограничивающие рамки для создания интересующей обстановки, синтезируется соответствующий начальный кадр, а затем создаются правдоподобные видеоролики. Помимо этого, модель может сделать мультимодальное прогнозирование сценариев движения, сгенерировав несколько правдоподобных развертываний на основе одного начального кадра.
Данная исследовательская работа является участником Конференции по машинному зрению и распознаванию образов, которая проходит в Ванкувере с 18 по 22 июня. Пока что представленная нейросеть является лишь исследовательским проектом и не ясно, когда что-то подобное NVIDIA выпустит в открытый доступ.





